MyDataHelps allows you to leverage randomization to create dynamic participant experiences for your research study.
In practice, this feature can be used to facilitate:
- Core components of the participant experience (e.g., defining participant cohorts)
- Micro experiments (e.g., determining receptivity to SMS vs push notifications)
- Everything in between (e.g., survey delivery time randomization, etc.)
When thinking about randomization, keep in mind the following factors:
- When should the randomization occur? How often?
- What are the different randomization groups?
- What is the weighting for each of these groups?
Randomization relies on two platform components: schedules and custom fields. Schedules dictate when the randomization will run and what the possible randomization groups are. Custom fields store the information for which randomization group a participant has been assigned to. Custom fields can then be used across the platform to dictate the effects of this randomization.
Implementing Randomization in your Project
See the general steps below on how to incorporate randomization into your project:
Using Schedules for Randomization
Schedule actions are helpful for conducting scheduled randomization.
- Create a custom field to store a participant’s randomization assignment.
- To use a custom field to create a schedule for randomization, the custom field must be set as a "text" type.
- To use a custom field to create a segment for randomization, the custom field may be set as a "text", "decimal", or "integer" type.
- Create a schedule to run the randomization.
- One time randomizations will likely use the "On Enrollment" schedule type.
- Daily randomizations will likely use the "Based on Participant Events" schedule type.
- Define the randomization groups in the "Update Custom Fields" schedule action.
- Select Set Value To "Random Value From List".
- Enter the list of randomization groups into the scheduler.

- Utilize the custom field throughout the rest of the platform
- This custom field can be used across the platform to curate unique participant experiences for each randomization group (e.g., deliver specific surveys or notifications to each randomization group, build dedicated segments)
Using Segments for Randomization
Segment actions are helpful for conducting unscheduled randomization on-demand.
- Create a segment to run the randomization.
- After creating a segment, select the "Actions" button. Then proceed to "Set Custom Field".
- Select "Random Value From List" and enter your randomization criteria.
- Click "Execute".
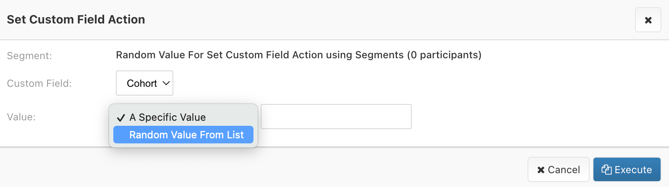
Participants in this segment will automatically be assigned a value based on your randomization criteria. The automatic assignment information is saved in the custom field.
Creating Non-Uniform Randomization Distribution
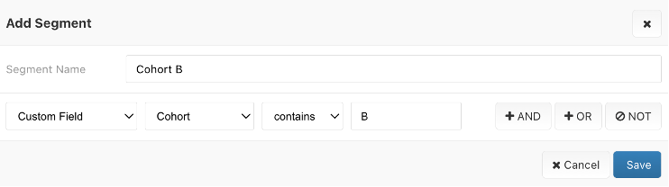
When aiming for a non-uniform randomization distribution (i.e., 25% Group A, and 75% Group B), you may choose to append an increment to the randomization groups (e.g., -1, -2, -3).
You can then use the segment feature and the “contains” filter to collect the incremented randomization groups into one cohort (e.g., Cohort B contains Cohort B-1, B-2, and B-3).
Advanced Randomization Options
If your project requires more advanced randomization, please find additional options below and contact us for further details on implementing in your project.
Permuted Block Randomization
Simple randomizations will trend toward a 50/50 distribution as you approach large numbers of participants, but can result in unequal distributions with small numbers of participants. Permuted Block Randomization ensures a 50/50 split when randomizing into cohorts without taking any additional parameters into account. For example, if you want an even split of participants in each cohort by sex at birth, this type of randomization will allow you to do so without complex configuration on your end.
For this type of randomization, the project team provides us with a table that includes specific instructions and a predefined order for how participants will be distributed across cohorts. For example, they may want participant 1 with A=1, B=0 and C=2 to be Cohort A and participant 2 meeting these same criteria to be Cohort B. It is more time intensive for the project team, because it necessitates creating a detailed table, but it allows for more control over how participants are distributed across cohorts.
Stratified Random Sampling
Stratified Random Sampling is similar to Permuted Block, except that it takes several parameters into account when assigning participants to different cohorts and allows for different percentages of distribution. The idea being, study teams can ensure all cohorts have a certain percent distribution of factors, such as age, recruitment site, or city. This form of randomization uses Custom Fields to set predetermined parameters and ensures those parameters are distributed across groups as specified by the project team.
For this type of randomization, the project team will need to share strata, such as age or gender identification, and percentages within each cohort and our system distributes as specified. For example, if a study has two cohorts and five study sites, the research team may want 20% of participants in each cohort to be from one of the five recruitment sites to make them evenly distributed. They may also want 15% of participants in each cohort to be under 18 years old, 50% to be 19-50, 20% to be 51-80, and 15% to be over 80. Stratified Random Sampling allows for this kind of complex distribution across cohorts with less manual effort on the side of the project team.